Knowledge Discovery in Databases Project
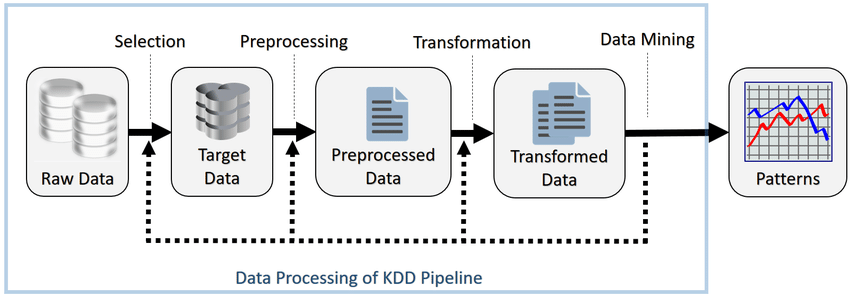
Questo progetto riguarda la Knowledge Discovery in Databases (KDD), ovvero un campo dell’informatica, che si occupa dell’estrazione dai dati grezzi di informazioni interessanti precedentemente sconosciute. Verranno illustrati i 7 passi necessari per realizzare tale processo. I dati fanno riferimento a un sistema di Intrusion Detection.
I 7 passi sono:
- Comprendere il dominio applicativo, i risultati e la certezza desiderati
- Selezionare i dati e individuare la rappresentazione. La lettura degli attributi può essere effettuata in modo statico (analizzando il codice), dinamico (eseguendo il codice) o un mix.
- Preprocessing: si analizzano gli attributi per verificare se i valori sono errati o mancati. Si utilizzano solitamente strumenti per visualizzare dati.
- Trasformazione dei dati: si trasformano i dati per essere accettati dall’algoritmo di data mining.
- Scelta del task e l’algoritmo di Data Mining: questo viene effettuato in base alla tipologia di output richiesta, alla sua qualità nel contesto e al formato dei dati accettati. Nel caso i dati non siano nel formato accettato, vanno ritrasformati.
- Individuare il valore dei parametri per l’algoritmo che diano il risultato desiderato
- Validare il pattern con altri dati. In caso di risultato negativo bisogna tornare indietro, quanto dipende dall’errore.
Nel caso del progetto i 7 passi sono stati realizzati nel seguente modo:
- Il dominio applicativo è stato compreso essere di un sistema di Intrusion Detection (IDS). Esso è stato creato dall’Istituto Canadese per la Cyber sicurezza (Canadian Institute for Cybersecurity - CIC), che fa parte dell’Università di New Brunswick. Il progetto di tale dataset è Intrusion Detection Evaluation Dataset (CIC-IDS2017). Per generare il traffico è stata realizzata una completa infrastruttura composta di modem, firewall, switch, router e computer, quest’ultimi aventi come sistema operativo Windows, Ubuntu e Mac OS X. Il dataset contiene statistiche sulle connessioni catturate dall’IDS e la loro classificazione come benevole o malevole. La generazione delle statistiche è stata effettuate mediante il tool CICFlowMeter, la cui descrizione è disponibile nella seguente pagina.
- Dei dati è stato selezionato un sottoinsieme caratterizzata 10000 esempi per la fase di train e 2000 per quella di test. Per la classificazione dei dati è stato utilizzato un attributo binario, dove il valore
1identifica il traffico normale e il valore0il traffico riguardante un attacco. - Attraverso le funzioni messe a disposizione dalla libreria Pandas, che è stata utilizzata anche per caricare il dataset, e dalla libreria Scikit-learn è stato possibile realizzare gli scatter e box plot e calcolare la Mutual information.
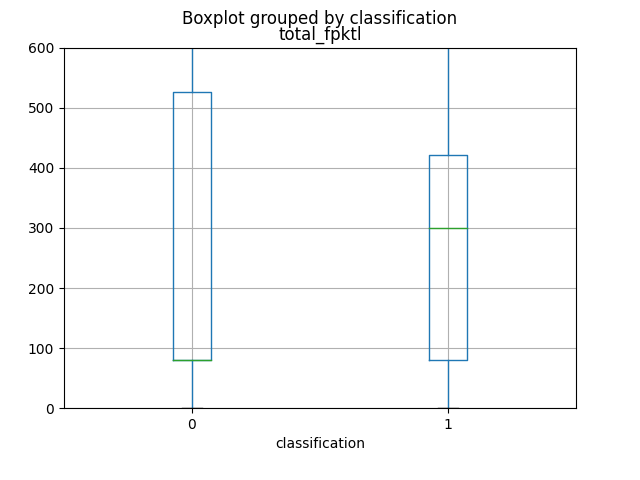
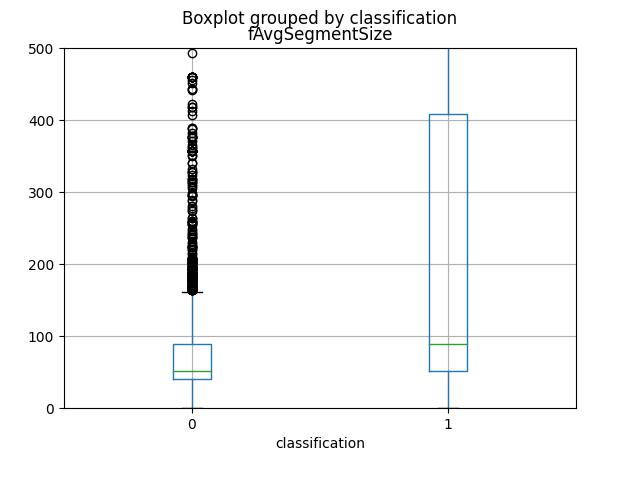
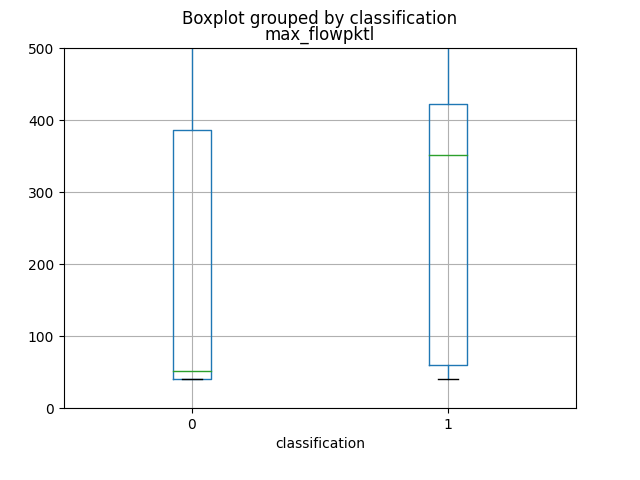
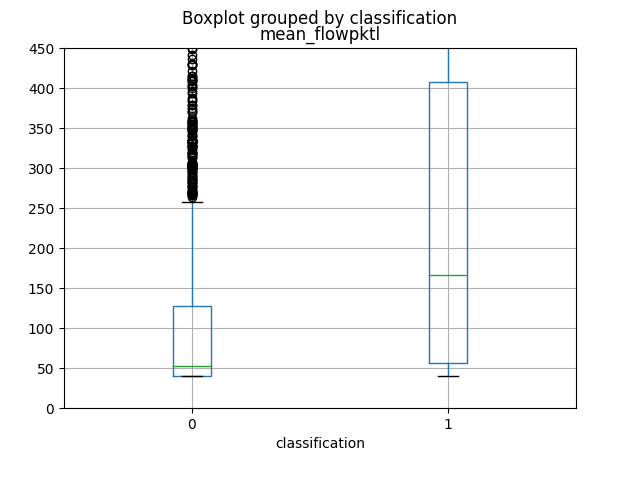
I primi 4 attributi che forniscono maggiori informazioni, come si può vedere dai grafici e dal calcolo della loro mutual information, sono in ordine total_fpktl, fAvgSegmentSize, max_flowpktl e mean_flowpktl.
- Siccome il dataset utilizzato risulta essere già in un formato compatibile con l’algoritmo di macchine learning non è stato necessario effettuare alcuna operazione di trasformazione dei dati.
- Attraverso una 5-fold Cross Validation sono state individuate le configurazioni migliori dei parametri di due Random Forest, una costruita sull’intero train set e l’altra costruita sulle 10 migliori componenti principali. I parametri e i rispettivi valori che sono stati valutati sono:
- max_features: indica il numero massimo di attributi da utilizzare. I possibili valori sono
sqrtelog2, che consistono nell’applicazione di tali funzioni al numero di attributi. - n_estimators: il numero di alberi nella foresta. I valori tra cui scegliere sono
10,20e30. - max_samples: indica la frazione di dati da utilizzare per costruire i singoli alberi. I valori da valutare sono
0.5,0.6,0.7,0.8e0.9.
- max_features: indica il numero massimo di attributi da utilizzare. I possibili valori sono
- Per scegliere la configurazione migliore per le due Random Forest è stata utilizzata la metrica F-score, che si basa sulle misure di Precisione e Recupero, andando a prendere quella con valore più alto. Dopo che queste sono state individuate sono state effettuate due operazioni. La prima è riaddestrare le due Random Forest sull’intero train set. La seconda è stata costruire un terzo classificatore. Questo terzo classificatore è un KNN che utilizza le due precedenti Random Forest.
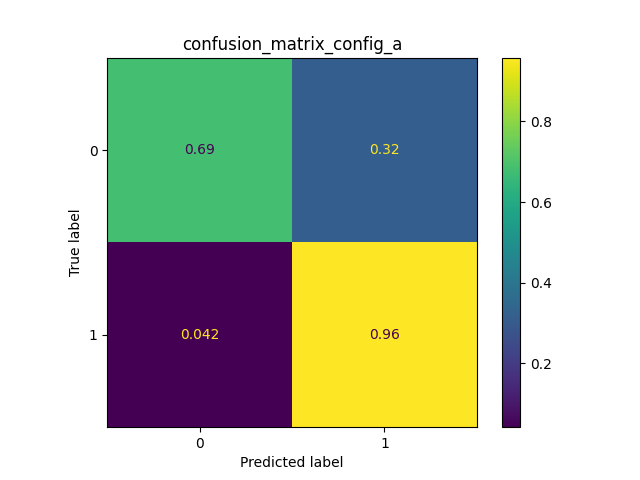
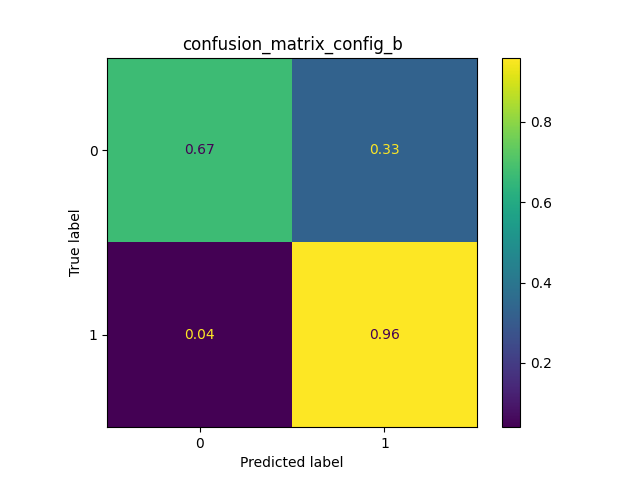
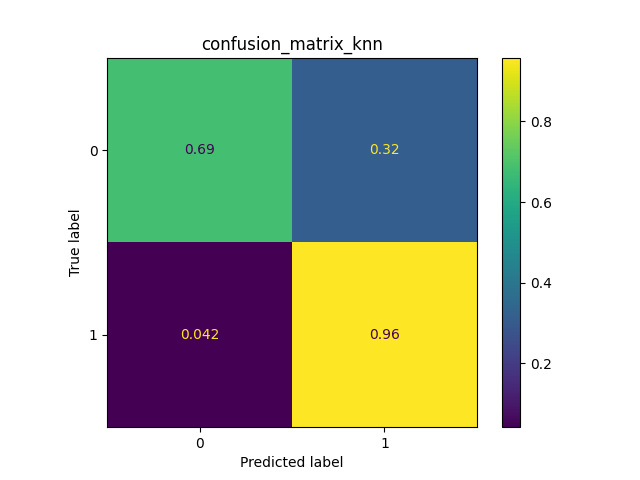
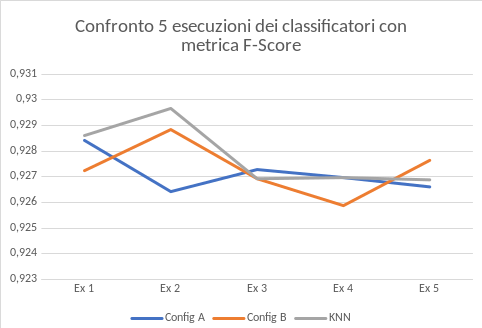
- Quest’ultima fase è dedicata a valutare i tre classificatori utilizzando il test set. Per effettuare ciò si utilizzano le matrici di confusione e il grafico della metrica F-score che proietta il risultato di 5 esecuzioni. Come si può vedere da essi il classificatore che ha portato i migliori risultati è il KNN. Questo classificatore unendo le due Random Forest permette di prendere il meglio di ciascuno.
Project link: https://github.com/Tecnomiky/data_analysis_for_security